Τι είναι ένα LLM;
Τα μεγάλα γλωσσικά μοντέλα είναι νευρωνικά δίκτυα εκπαιδευμένα σε τεράστια corpora κειμένου — βιβλία, άρθρα, κώδικα και περιεχόμενο ιστού. Μαθαίνουν στατιστικά patterns γλώσσας και μπορούν να προβλέψουν το επόμενο token σε μια ακολουθία, πράγμα που τους επιτρέπει να δημιουργούν συνεκτικό κείμενο, να απαντούν ερωτήσεις, να συνοψίζουν έγγραφα και να ακολουθούν οδηγίες όταν γίνει fine-tuning ή σωστό prompting.
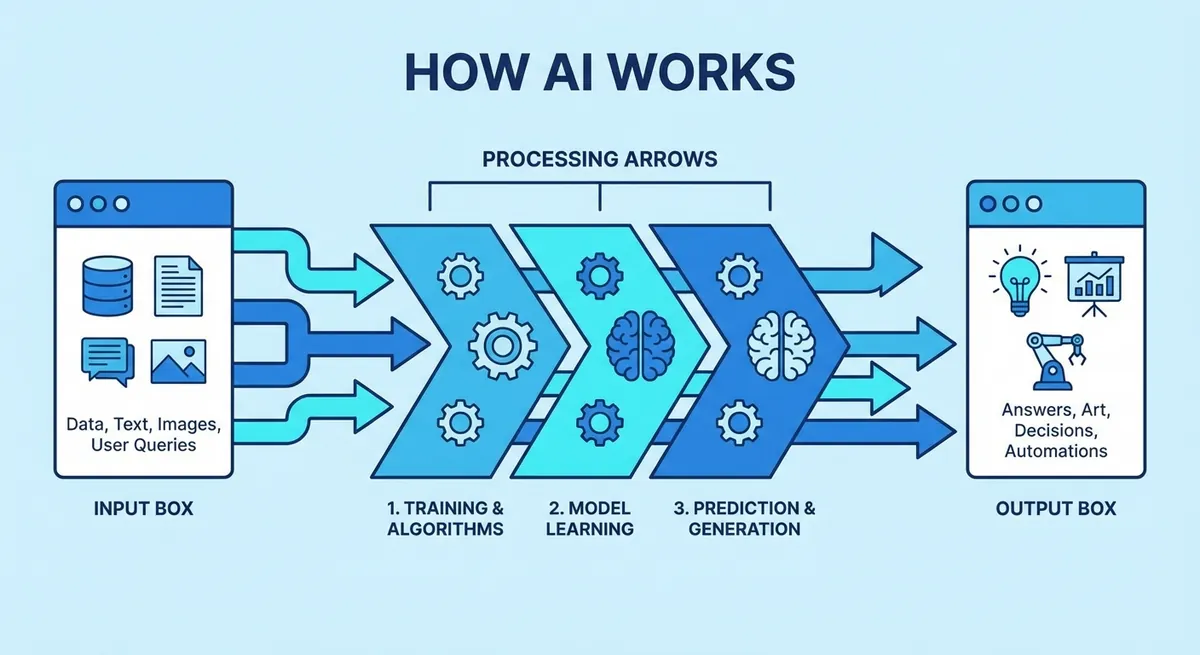
Πώς διαφέρουν τα LLM μεταξύ τους;
Μοντέλα όπως Claude, GPT και Llama διαφέρουν σε μέγεθος, δυνατότητες και κόστος. Τα μικρότερα μοντέλα τρέχουν ταχύτερα και φθηνότερα αλλά μπορεί να στερούνται λεπτομέρειας· τα μεγαλύτερα μοντέλα χειρίζονται πολύπλοκη συλλογιστική αλλά απαιτούν περισσότερη υπολογιστική ισχύ. Για production συστήματα, η επιλογή εξαρτάται από τις απαιτήσεις καθυστέρησης, τις ανάγκες ακρίβειας και τον προϋπολογισμό. Τα LLMs αποτελούν τη βάση των περισσότερων σύγχρονων εφαρμογών τεχνητής νοημοσύνης.