What is an LLM?
Large language models are neural networks trained on enormous text corpora — books, articles, code, and web content. They learn statistical patterns of language and predict the next token in a sequence, which lets them generate coherent text, answer questions, summarize documents, and follow instructions.
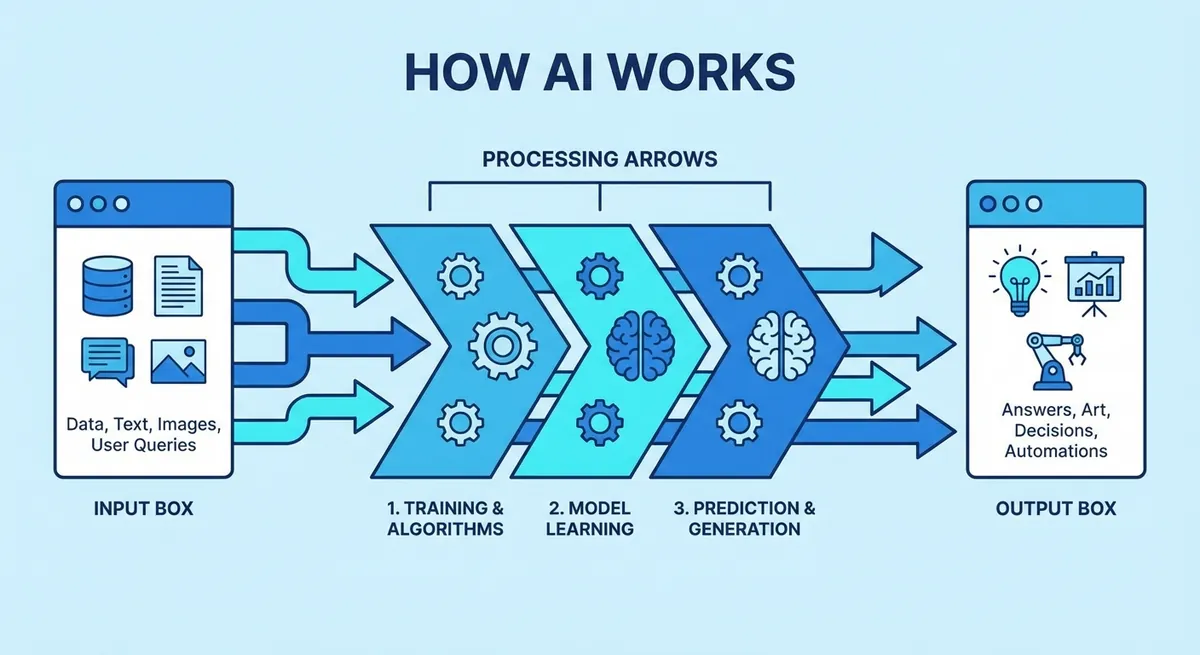
How do LLMs work?
Modern LLMs build on the transformer architecture from the 2017 paper Attention Is All You Need. Training produces a fixed set of weights — billions of numbers that encode what the model knows; at inference you send it tokens and it returns more tokens, one at a time. Models like Claude, GPT, Gemini, and Llama differ along three production axes — capability, latency, and cost per token — and many systems route between several models depending on the task.
An LLM alone is not a complete system: it has no persistent memory between calls, no native access to your data, and no way to take actions. Production setups pair it with RAG for fresh facts, agents for multi-step work, and fine-tuning for consistent domain behavior — and are evaluated on your own prompts and data, not marketing benchmarks.