What is a vector database?
A vector database stores embeddings — lists of hundreds to thousands of numbers that capture the meaning of text, images, or other data — and finds the entries closest to a query vector. This enables semantic retrieval: matching by meaning rather than keywords, so a search for "how do I cancel my subscription" surfaces a doc titled "Closing your account" without sharing a single word.
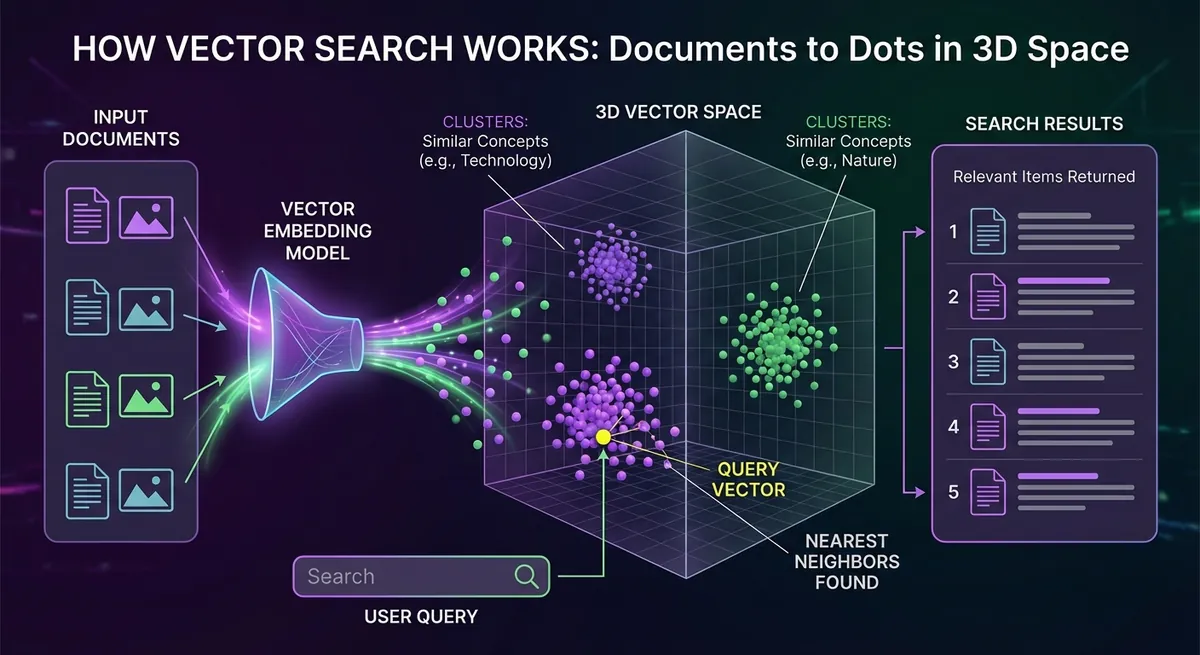
Comparing a query against every stored vector is too slow at scale, so vector databases use approximate nearest neighbor indexes (HNSW, IVF) that trade a little recall for millisecond queries across millions or billions of vectors. The options span hosted services (Pinecone, Weaviate), Postgres extensions (pgvector) for moderate workloads, and self-hosted open source (Qdrant, Milvus) for strict data-residency or cost requirements.
What are vector databases used for?
Vector databases are the storage layer that makes RAG practical at scale; they also power recommendations, duplicate detection, semantic code search, and any feature that asks "find things like this one" rather than "find the exact match."